Automatically generate a Customer Decision Tree for a category of products in Retail
Understand the shopper behavior in the food retail industry is a complex and time consuming task. Generally retailer launch customer interviews campaign to understand the customer decision tree on a particular category. In this article I will share an approach that I am using to generate the Customer Decision Tree using advanced data analytics.

The retailer’s challenges
While the food industry and the global brands continuously extend their offer, the category managers in retail have all the difficulties to fit the available assortment in their stores. Indeed the space allocated for a particular category is limited and it can quickly become congested if no category management is done to avoid the product proliferation.
By category management, the retailer need to answer to the following main questions :
1/ What is the optimal space allocated for the category?
2/ What is the optimal assortment for the category ?
3/ How the category should be segmented in the aisle, according to the customer flow ?
4/ What is the optimal space allocated by product (facing), and where to display the products ?
In order to get an answer, the retailer need to deeply understand how the customers are purchasing within a category. It sounds like retailer need to understand exactly why a customer bought a particular product, and which product he will buy if the product he is looking for is not available on the shelves, what we call the ‘demand transfer’.
If a category manager is able to understand it, he can efficiently build the category assortment by keeping only products that are very important for the customers (meaning there is no ‘demand transfer’) and remove products that have a high ‘demand transfer’.
One customer = one behavior
As a customer, we all have a purchase behavior and we know how to answer to the previous challenge for our personal case. But how to catch this behavior for thousands of customers ?
Traditionally the retailer used a panelist company that runs huge campaign of customer interviews, trying to understand how they will purchase within a category.
Example, a retailer wants to understand how the customers are purchasing on the Pasta Category. They start to interview their customers and the decision tree can have many different structures :
- Brand → Shape → Weight → Type of wheat
- Weight → Shape → Brand → Type of wheat
- Type of wheat → Weight → Shape → Brand
……
For the first option, it means that customers are very loyal to the brand as it is the first entry’s key for the category. The demand transfer between brands in this case is very low, so the retailer should focus on top brands and group all the products by brand.
Well, but what if each customer has a different decision tree? In fact this is the case.
Don’t ask customers, look the data
It is quite obvious that the customer behavior extracted from the panelist can be identified through the purchase history of each customer. That’s where analytics can help !
Retailer have a secret weapon for it : the loyalty card. They are able to track each customer purchase history and generate a global pattern for each category.
The method I will describe uses a similarity coefficient (Yule’Q) between products within a category, and the spicy.cluster.hierarchy module to generate a dendrogram which will group the products.
The dendrogram will be then analyzed by the category manager to try identifying patterns in the generated groups. He may see that products are grouped by brand, or any another attribute. He can then extract a decision tree for the category and use it during the category management process.
Let’s go !
For the accuracy of the example, I am going to use real retailer data, for confidential reasons I will then hide all sensible informations. We will focus on the pasta category as it is not very complex to analyze.
Data used :
- Customers transactions details (data generated when customers check out at the cash counter)

- Customer segmentation (using RFM methodology)

Steps :
- We need to calculate the similarity for each product with each of the other products. Thus the first step is to create the list of combinations (couple of products).
- We will remove products with the total quantity sold below the first threshold
- Then, we will identify the customers who bought at least one time the products present in the couple.
- For a couple with product A & B we will calculate the following :
- In how many transactions none of the products was there ( a )
- In how many transactions B was alone ( b )
- In how many transactions A was alone ( c )
- In how many transactions A & B was together ( d )
Calculate the Yule’s Q coefficient as : (1+(a*d-b*c)/(a*d+b*c)). You can of course use a more accurate coefficient.
- When similarity coefficient is done for all the couple, we remove the couple with total transactions (a+b+c+d) below the second threshold.
- Generate the dendrogram
Code :
cdt_by_product(data,"Pasta Products",["High-Value","Mid-Value"],5000,500)Ouput :
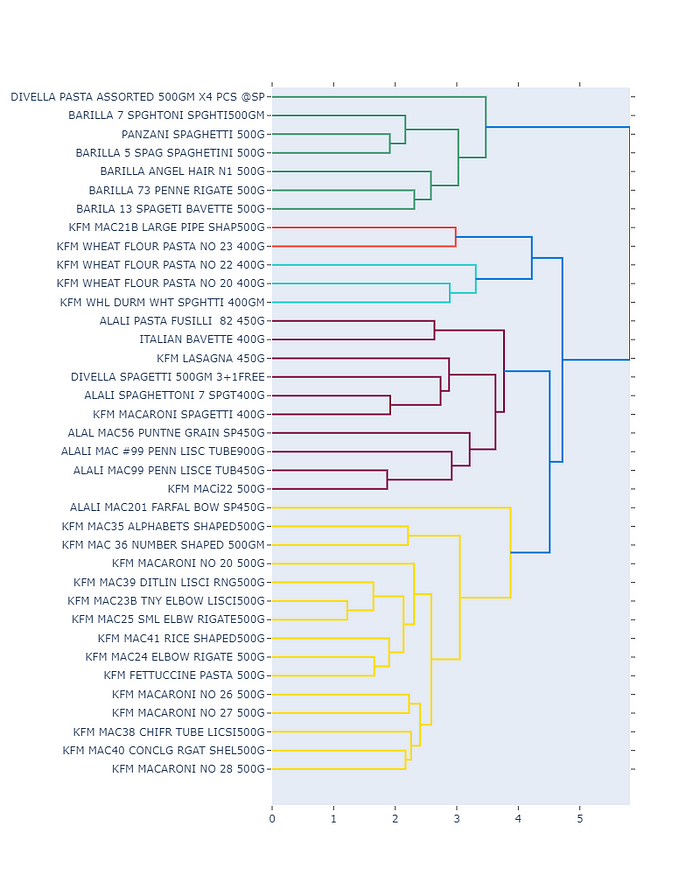
In this simple (and not optimized) example we see 5 colored groups. Some patterns are visible ; frequency of brand in each group / type of wheat / shape. The products present together in the same group are more likely to have a higher demand transfer.
The groups generated can now be analyzed by the category manager who will try to see patterns inside. It is not a straight approach and the Customer Decision Tree generated depend on the function’s parameters which are :
- The minimum quantity sold per product (here a statistic analysis on the total quantity sold per product can help).
- The minimum quantity sold per couple of products.
- The customer segment (we need customers who are the most loyal as we can then expect that all their transactions are flagged with their loyalty card number)
- The stores can also be added to the parameters (as you analyze the full assortment you need to consider stores having the full assortment)
Another interesting way is to generate a dendrogram not by product but :
- By brand
- By supplier
- By family of products
- By sub-family of products
In practical you will need to generate many dendrograms, by optimizing the parameters, to generate a comprehensible & useful customer decision tree that can be analyzed by the category manager.
